Online Speculative Decoding
LLMs (Language Models) are at the forefront of revolutionizing contemporary applications and a growing number of companies are seeking to deploy LLMs. Nonetheless, a pivotal factor that demands careful attention during deployment is latency. Current generation systems exhibit high latency, much of which can be attributed to the auto-regressive nature of the generation process. This necessitates generating tokens sequentially, where each forward pass of the model produces just one token.

Auto-regressive nature of token generation: one token is generated each time.
To generate each token, there’s a need to transfer the model weights from HBM (High Bandwidth Memory) to SRAM (Static Random Access Memory) and access the key-value cache of all previously generated tokens. For LLMs with billions of parameters, this procedure places a substantial demand on memory bandwidth, subsequently resulting in the suboptimal utilization of the GPU.
In the following sections, we’ll first introduce speculative decoding, a technique designed to reduce the inference latency by offloading the majority of seuqential generation workload to a much smaller draft model. We will then highlight practical challenges in speculative decoding and unveil our key observations that contribute to our proposed online speculative decoding algorithm (OSD) with improved responsiveness, speculation accuracy and compatibility with LLM serving systems.
Speculative decoding
Specualtive decoding is first introduced by this paper. Put simply, speculative decoding recognizes that some tokens are straightforward to generate, while others are more challenging. To address this, we can utilize a streamlined ‘draft’ model for the easier tokens and a more comprehensive ‘target’ model for the complex ones. Specifically, to ensure that speculative decoding produces identical output to the original generation method, the draft model proposes tokens which are then validated by the target model.
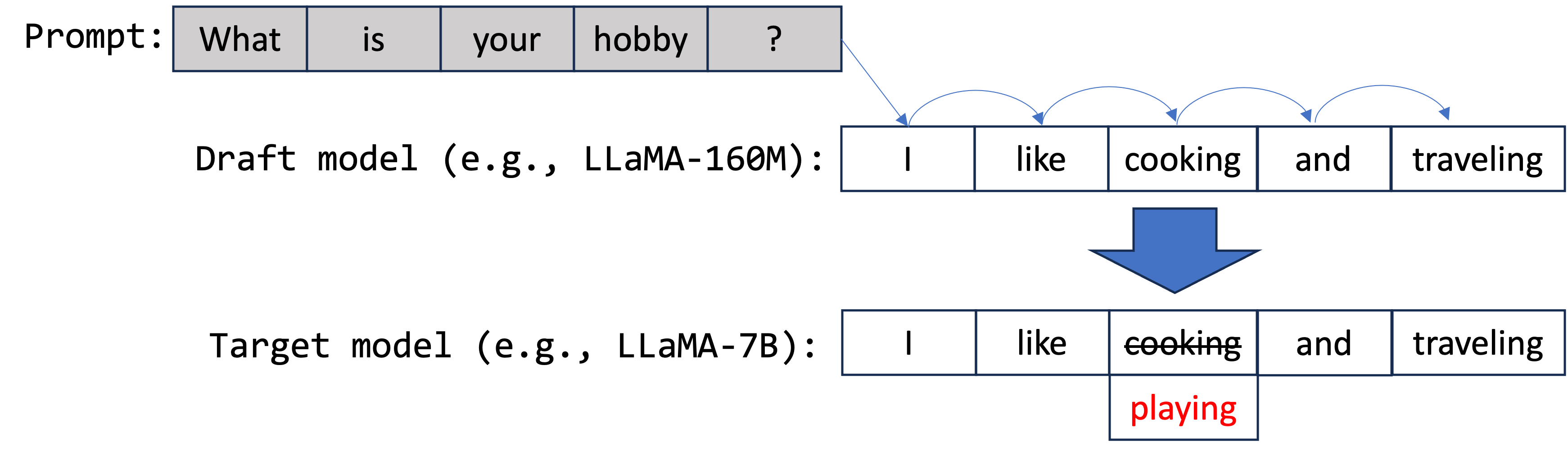
As shown in the picture above, the draft model proposes five tokens: ["I", "like", "cooking", "and", "traveling"]. These are then forwarded to the target model for parallel verification. In this example, the third token, cooking (should be playing), was proposed inaccurately. As a result, only the first three tokens, ["I", "like", "playing"], are generated in this step.
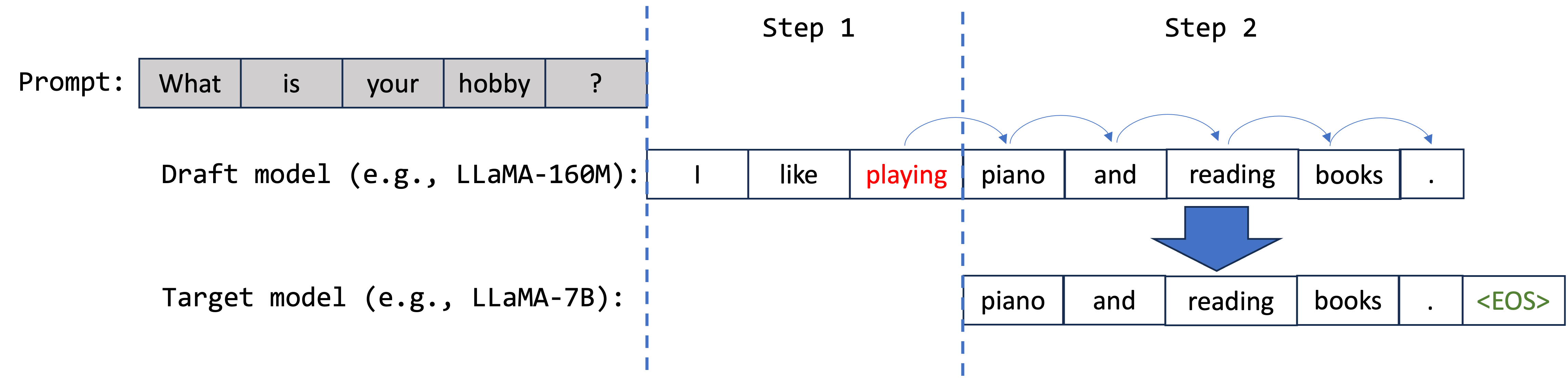
For the second step, starting from the playing token, the draft model proposes a new set of tokens: ["piano", "and", "reading", "books"]. Let’s assume, fortunately, that all these tokens are accurately proposed and subsequently confirmed by the larger model. Additionally, the larger model produces an extra token, <EOS>, based on the last verified token .. The generation process concludes at this point since the end-of-string token (<EOS>) has been produced.
Why can speculative decoding reduce latency?
Speculative decoding aims at transfering the majority of workload to a much smaller draft model. The draft model retains the autoregressive nature, generating tokens one at a time but with a significantly faster speed. The target model can validate multiple generated tokens from the draft model in a single forward pass (refer to the paper for more detail)
For instance, in the example above, ["piano", "and", "reading", "books"] tokens are verified by the large target model in a single forward run. Consequently, speculative decoding helps amortize the overhead of loading model weights and key-value caches. Originally, each token required accessing the weights and key-value cache, but now it’s reduced to just one access per $k$ tokens, where $k$ represents the number of accepted tokens in each generation step.
Online speculative decoding (OSD)
Key observations that pave the path towards improved speedup
Performance of the original speculative decoding algorithm depends heavily on one or a set of reliable draft models. In practice, open-domain draft models has poor speculation accuracy. Furthermode, it’s hard to predict query distributions and prepare specialized draft models offline to ensure speculation accuracy. To address the eixsiting challenges and seek new ways to improve speculative decoding in real LLM serving systems, we first present several interesting observations and then introduce our solution:
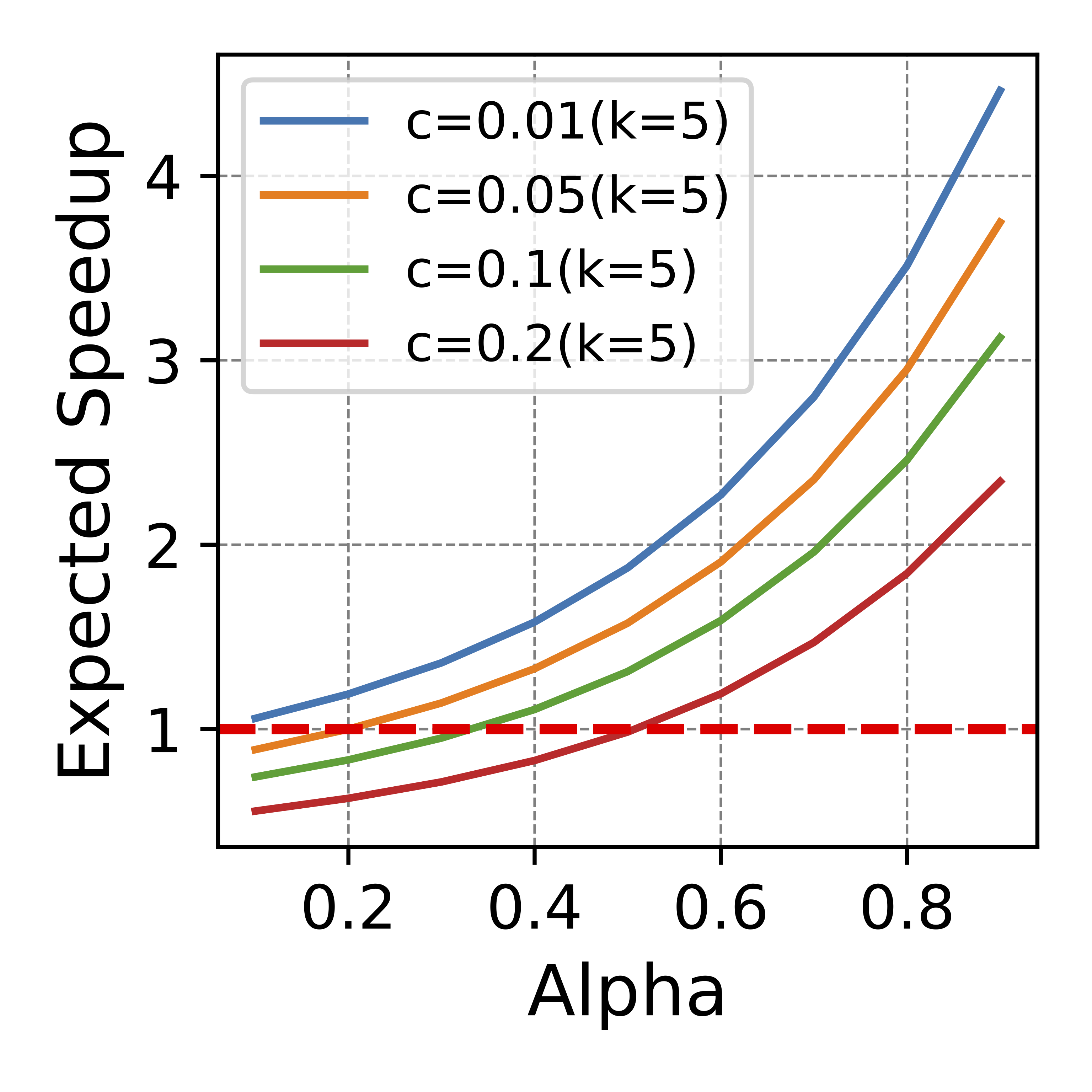
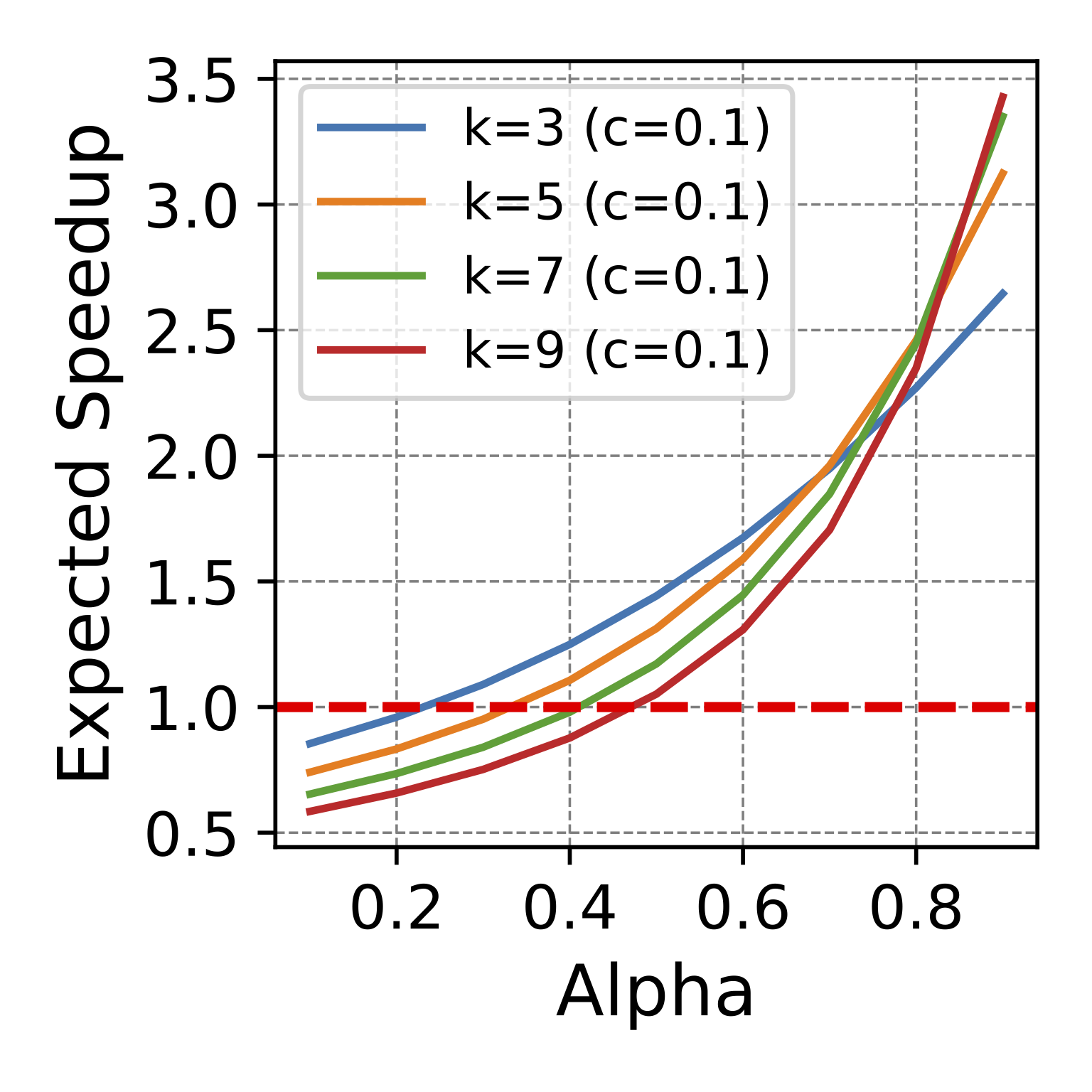
c: the time ratio for a single run between the draft and target model. k: number of proposed tokens each step. Alpha: token acceptance rate.
- Better token acceptance rate leads to more speedup. The draft model must approximate the target model sufficiently to achieve latency reduction. We employ Alpha to denote the speculation accuracy, defined as the expected token acceptance rate. For instance, if the token acceptance rate is 0.7, it signifies that, on average, 70% of tokens proposed by the draft model will be accepted by the target model. As illustrated in the figures above, for smaller values of Alpha, speculative decoding can even lead to performance degradation, as evident by a speedup factor falling below 1. This is particularly notable when dealing with a sizable draft model. Furthermore, the relationship between speedup and Alpha exhibits a superlinear behavior; doubling the acceptance rate can result in a speedup exceeding 2x.
- Distillation boosts token accpetance rate. Speculative decoding detects inaccuracies within the smaller draft model and provides correct solutions for these inaccuracies. In the specific example provided above, we can discern a proposal error when the
cookingtoken is suggested, whereas the correct token should beplaying. Furthermore, we have access to the probability distribution associated with these two tokens. This essentially means such information can be harnessed to refine the draft model through distillation, thereby enhancing the draft model’s token acceptance rate, all without incurring any additional labeling costs. Additional evidence provided in the experimental section further underscores the effectiveness of distillation in improving the draft model’s token acceptance rate. - There are many spare FLOPs in the serving system for distillation. Spare FLOPs’ refer to the unused computational capacity during regular operations, primarily because (1) LLM inference is memory bandwidth bound instead of computation bound, and (2) LLM serving systems are often provisioned with resources exceeding the needs of the average workload. These spare FLOPs represent latent computational power, which can be harnessed for auxiliary tasks without compromising user experience. In our context, these spare FLOPs can be utilized to conduct gradient updates on the draft model, adapting it to shifts in query distribution.
OSD architecture
Based on the observations above, we propose the online speculative decoding (OSD) algorithm to speedup LLM inference:
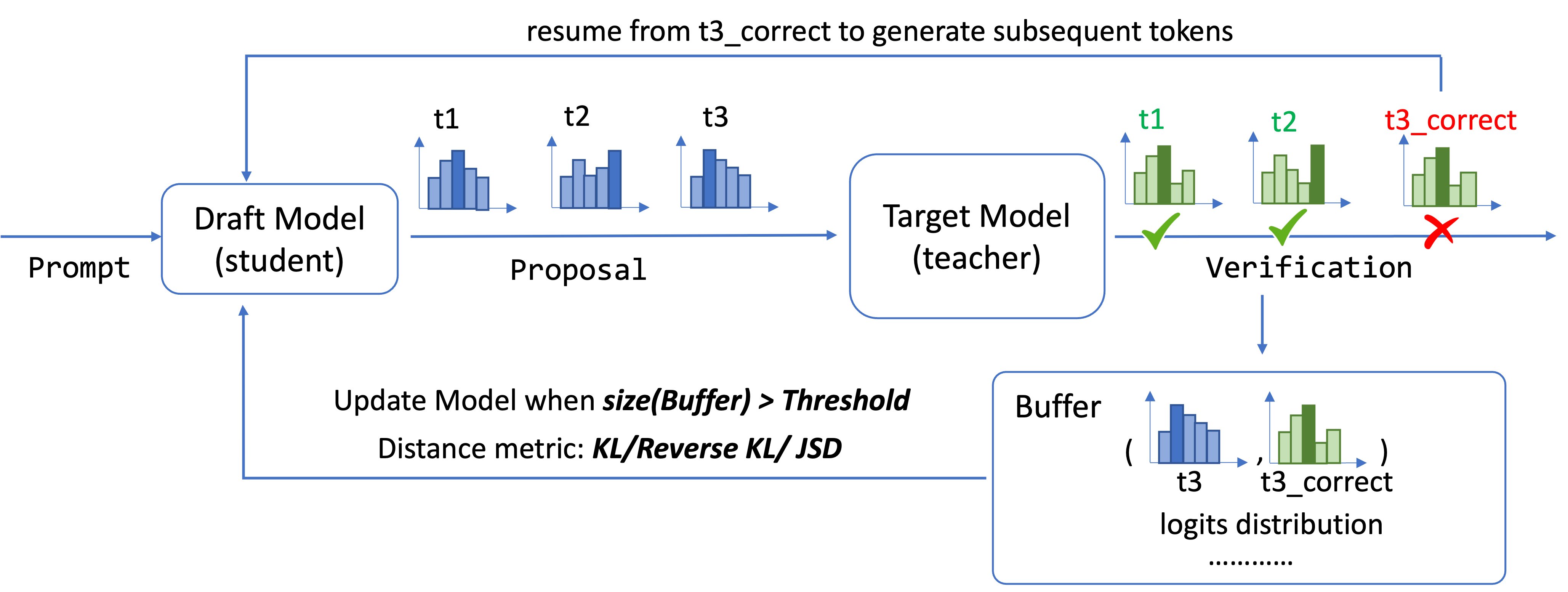
For each prompt, the draft model suggests multiple tokens in a single step. The target model then verifies these tokens, accepting some and rejecting others. If the student proposes incorrect tokens, both the draft and target distributions are stored in a buffer. Once the buffer exceeds a specified threshold, the draft model is updated by calculating the loss between the draft and target distributions using various distance metrics. Overall, OSD continuously improves the draft model’s approximation (indicated by increased token acceptance rate Alpha) by learning from the target model during the serving phase.
Experiments
Online learning: There are two important questions to anwer here: (1) Does the online algorithm increase the token acceptance rate? And is this enhancement comparable to the rates achieved in offline settings, which serve as an upper bound given their full access to data? (2) How quickly does the online algorithm increase the token acceptance rate?
In this experiment, we pick LLaMA-160M as the draft model and Vicuna-7B as the target model. In the beginning, online speculative decoding yields a lower token acceptance rate in comparison to the offline distilled model. Nevertheless, these acceptance rates rise swiftly as the draft model is exposed to more data. We also annotate the token acceptance rate from the offline setting to highlight the potential peak performance that the online serving system could reach.

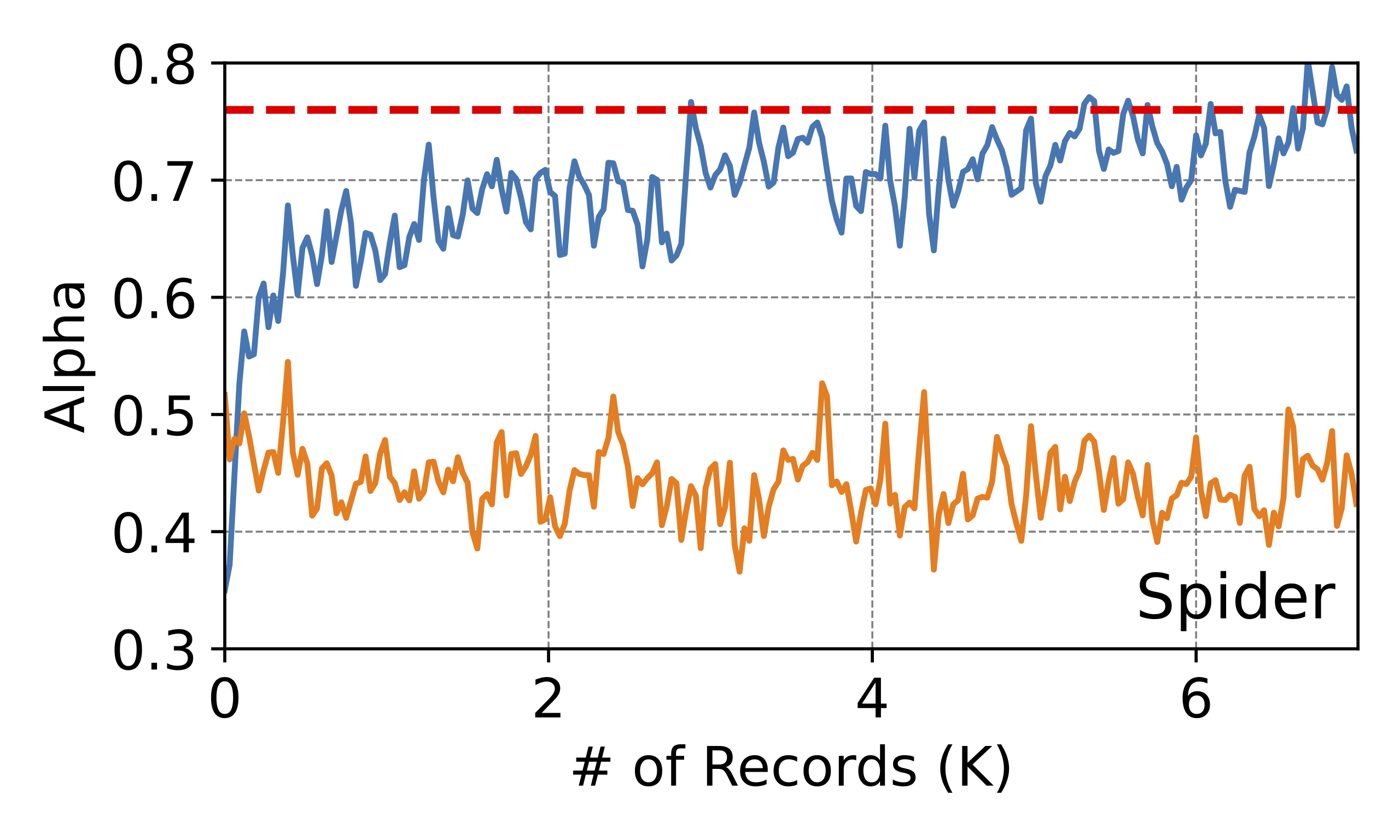
The x-axis represents the number of records that OSD has processed. Alpha is averaged over the most recent 50 records.
Distribution shift: In this experiment, we want to know how quickly can OSD adapt to distribution shift. As shown below, OSD’s alpha value dips notably at distribution boundaries (around 2K, 4K, and 6K records). This is anticipated since the draft model initially struggles when faced with a new distribution. However, the alpha value rebounds quickly as OSD processes more data, highlighting its adaptability to shifting query distributions.
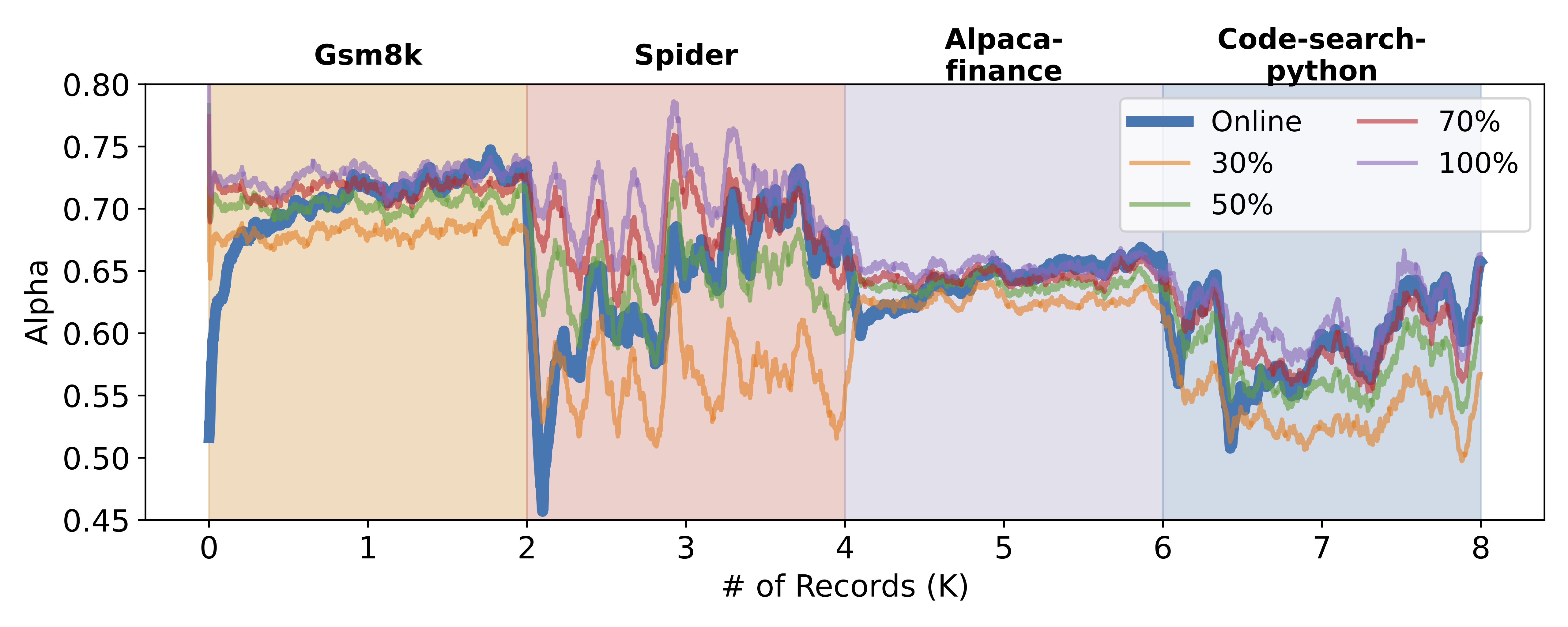
We also compared our results to those from a static setting. To ensure the draft model wasn’t just memorizing data, we chose samples distinct from the online evaluation data. These samples correspond to 30%, 50%, 70%, and 100% of each dataset’s online evaluation volume, at 0.6K, 1K, 1.4K, and 2K quantities respectively. As depicted, upon an initial shift in query distribution, OSD’s performance aligns with or slightly trails the distillation with 30% data. However, it quickly catches up, matching or even surpassing performances seen with 70% to 100% data access. This highlights OSD’s ability to rival models fully exposed to the query distribution, even without intimate knowledge of the underlying query dynamics.
Arena dataset:
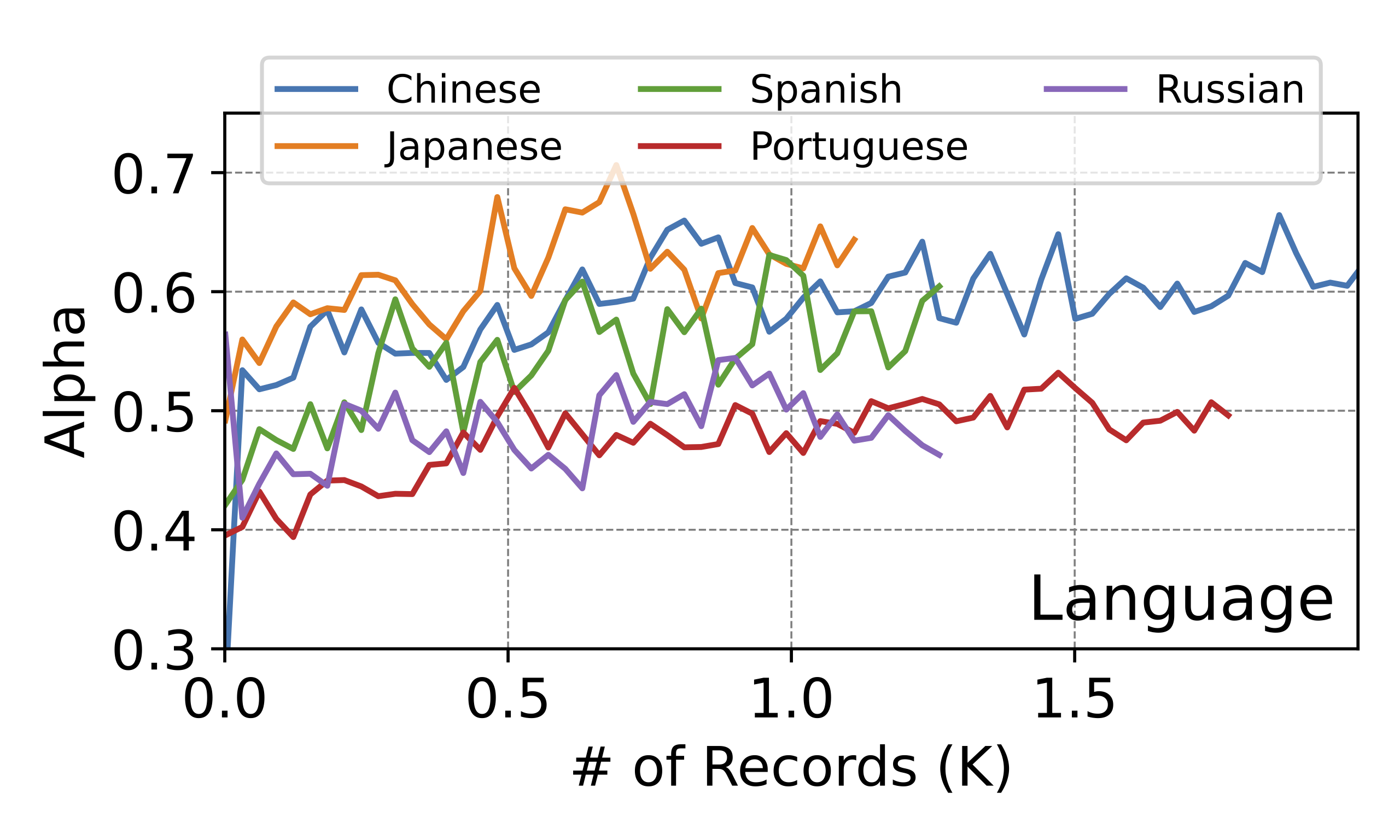
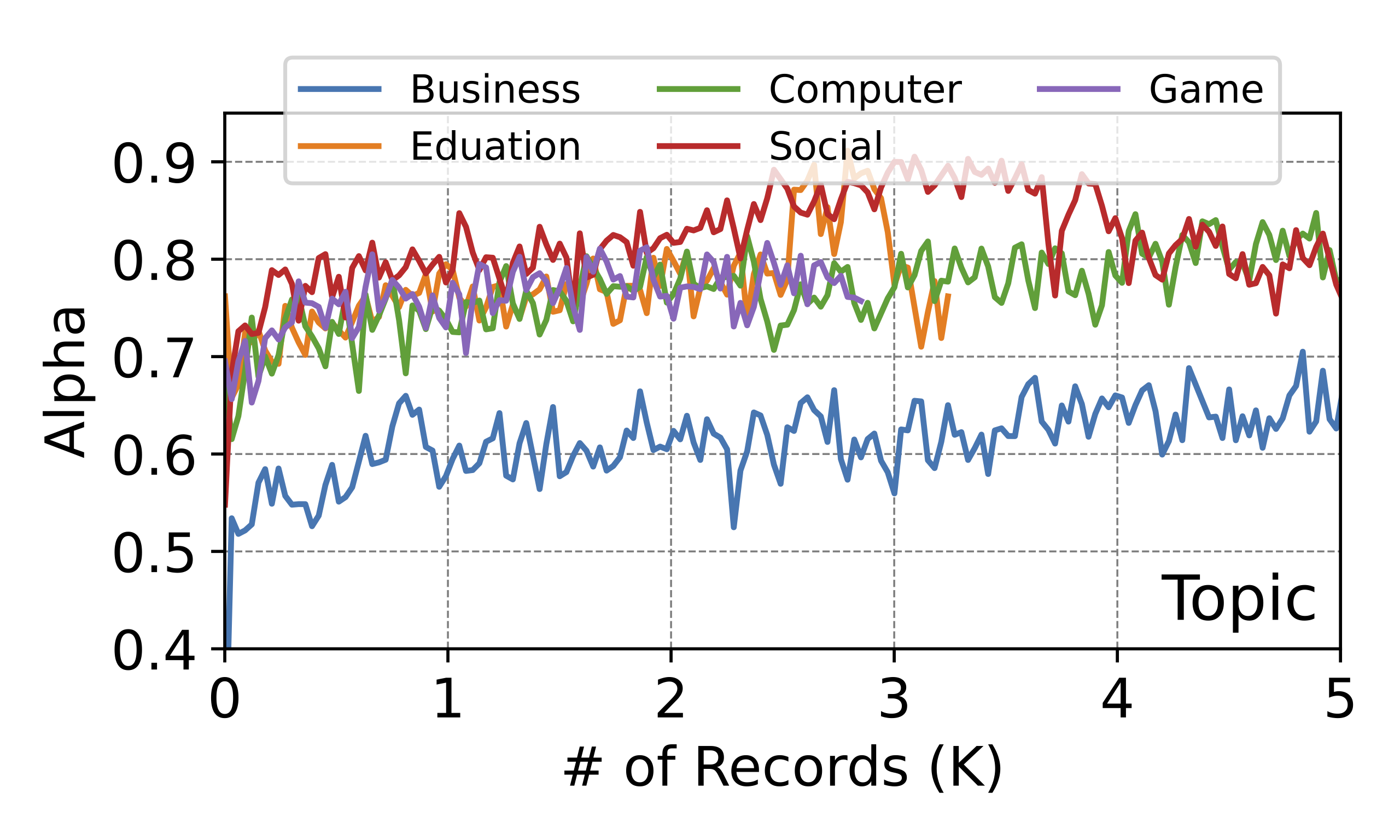
We evaluate OSD on real LMSYS-chat conversations that span 4 months. First, we categorize conversations based on the language and we focus on conversations among the top five languages, excluding English. For every chosen language, we use an independent LLaMA-160M to serve as our draft model. All draft models share the same Vicuna-7B as the target model. The token acceptance rate, averaged over the latest 100 requests, reveals that OSD’s enhances rates by 0.1 to 0.2, even with under 2K data points. We also clustered English conversations by topics using the fine-tuned distilled bert model, focusing on the top five. As shown above, acceptance rates are above 0.6 across topics, with Social and Computer discussions peaking near 0.8.
Final words
We invite you to refer to the OSD paper for comprehensive details! While we plan to release the code to replicate the results presented above, it’s important to note that this code is not a real serving system; rather, it serves as a proof of concept for the idea. We are actively engaged in the development of a fully operational system, so please stay tuned for further updates!